
开拓者——面试笔记分享
江中炼-2015-12
开头须知:
如何验证自己的学习情况?
那么去更牛逼的公司面试吧!别做井底之蛙…
谢谢…
还记住一点,别泄气、别绝望、因为我的体验告诉我,很多公司不了解你的人,只能从他的角度看你,却忽视了你的特点…
走出去的目的是认清楚你的现状,别被现在安稳的工作所迷惑了,继续加油吧!!!
想考验自己,那么就走出去看看…
世界和我爱着你
开始从团队的创建说起吧,这个慢慢衍生了好多项目。
1. 反作弊团队的起源:
京东的整个数据营销业务部 从2014年4月份左右开始。
主要的员工,还是来至于 BAT和其他的互联网公司。
反作弊团队,就是从2014年6月份正式成立,我入职的时间在7月底。
2. 反作弊团队的贡献:
第一个项目: CPS反作弊
对于京东来说,CPS(Cost Per Sale):以实际销售产品数量来换算广告刊登金额。
对于发展中的京东而已,这个起着很大的作用,京东一直主打正品行货,从用户的角度考虑问题,这一点,也是我看好: 目前CEO刘强东的一点。(当然附属:物流)
其实这一点与拉勾网 从用户角度考虑问题的方式比较相似:
例如我面试通过 -> 一拍快速的找到合适的工作和岗位一样。(帮助用户,进行曝光)
从商品的角度来讲,热卖,意味着优质的商品,能得到最大限度的展示。
所以有很多 CPS联盟商家,会选择一些热卖的商品或者一些特色的一些商品(主要是推荐与用户相符合的商品)这样,会增大我们的roi(投资回报率),极大的刺激京东的GMV,为此京东会付出相应的佣金。
那么问题来勒,林子大了,为了钱,很多联盟就会做出一些过分的事情,相互劫持。
常见的劫持方式简单介绍几种: (收集于网络, 解决方案请自行百度)
当然,我们需要分析,找特征,怎么判断这次行为是否异常,或者是否有价值?
1.分析技术: R/hive/Execl,进行统计分析
2. 项目相关框架: python/hive/scala/spark
1. 举个简单的例子: 我们如何分析一个联盟的质量高低???从而分析他的作弊情况
质量高低,最显著的就是 CTR点击率(点击/展现) 和 CVR 转化率 (订单/点击)
2. 我们如何评估这个好坏的标准呢?
最基本的: 均值、中位数、众数。
3. 那么如果评估最好和最差的呢?
标准差 +- 1~4 * 方差
4. 如果稍微有意思一点,我们可以通过花: 箱线图 来统计分析,效果
5. 当然可以通过散点图,来观察他们的密集程度,找出比较异常的区间。
6. 涉及到一些异常检测的知识,大家可以自行百度一下
好了~ 基本上人家大致知道你的业务水平勒。(后面应该就不会怎么问勒)
3. 技术方向:
Hadoop(万金油答案)
谈到了hadoop,那么他有什么好处呢?
1. 容错性 (hdfs 冗余备份机制/mapreduce 心跳机制,维持job正常完成)
2. 高效性 分布式文件系统,处理海量数据这也是他的优势
3. 扩展性 就是可以利用多台机器,进行分布式文件存储
4. 廉价性 降低开发成本,开源免费,硬件要求不高
(讲完以后,你就可以画一画mapreduce的底层计算的原理)
Hive:
那么我们再做项目遇到了哪些问题,有哪些新的体会???
其实,对于我来说,用的最多的就是 HIVE,建模、数据采集、数据清洗、数据分析、性能调优。
简单聊聊,这个框架的性能调优,这个我研究比较多。
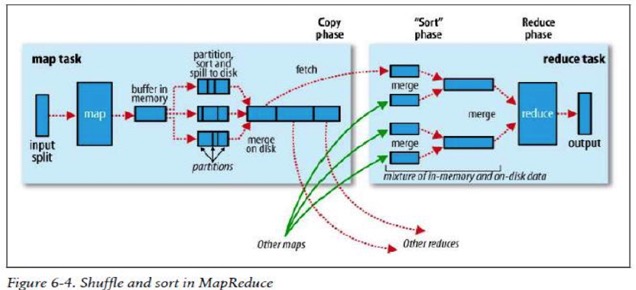
map 阶段和 reduce 阶段的输出,生成文件块和网络带宽的区别
map 阶段分组排序,(分组,求均值就会出问题; 例如: 11234 分组/4 不分组/5 )
reduce 分发:hive.groupby.skewindata=true; 有数据倾斜的时候进行负载均衡
Spark(大致原理)
谈到spark,那么spark到底是一个什么呢?

1. RDD Objects 割化为 DAG 图
2. DAGScheduler 分解 DAG图 为 Stages
a. RDD graph
b. Scheduler
c. Block tracker
d. Shuffle tracker
3.Stages 提交 task给 Task Scheduler来运行
a. 提交前会向 Cluster Manager进行注册, 申请资源
b. 分配到资源后,把 task分配到各个节点Worker上面去
c. Worker就 Threads (多线程的方式执行) 任务
standalone: 调度器 TaskScheduler
YarnCluster: 调度器 YarnClusterScheduler
YarnClientCluster: 调度器 YarnClientClusterScheduler

面试 4家公司:
1.拉勾网:
a)工作环境优雅,工作强度一般
b)偏向工程和技术
c)数据分析和数据挖掘方向比较薄弱。
2.艺龙
a)工作环境优雅,工作强度没感觉
b)偏向技术和基础数据平台的搭建,很 easy 的面过勒
c)业务为公司的核心吧,数据统计和分析显得有点重要
d)和他们老大聊了聊,感觉比较传统。
3.360(好搜)
a)工作环境安静。
b)思维能力和编码能力
c)如果懂爬虫和调优更好一点
d)简单介绍一下自己和你的项目
e)现在考一个思考题和你写写代码。
f)离开前,他说:坚持写你的博客,做好自己,加油!
4.APUS
a)工作环境非常好,感觉好像很轻松,但是没有人闲下来,也很安静。
b)纯深入的数据分析和数据挖掘
c)我大学辍学,所以很多知识点没有学得很好,然后就创业工作勒。
d)你是算法工程师??
e)问题: 你能写一个 xxx 公式吗? 你知道什么叫数据分析吗? 你知道数据分析需要具备什么吗?
f)你用过逻辑回归,你知道它的优势和劣势? 能简单分析一下吗?
g)然后叫一个小妹妹过来说:不好意思,今天面试就到这里!!!
问题来了:
我彻底被鄙视勒,在后面2家公司,突然觉得自己一无是处,感觉我特么像个傻逼一样,这4年来白白浪费勒。
后来也算是想明白勒,我擅长什么,我会什么,我写得简历是什么???
是我傻麽?
个人简历:
我做过反作弊项目,日常任务: 原始数据采集,数据表设计和维护,数据清洗,数据分析,数据挖掘(涉及部分)
1)广告CPS反作弊分析
1. 负责广告作弊数据的采集
2. 负责广告的作弊数据处理/分析
3. 负责作弊的表结构数据的设计
4. 负责HIVE 的性能优化
我想难道,他们都不懂,HIVE 是干嘛的吗? 难道不知道我2年半的项目都是强调的是这个吗?
我简历一致强调:自学能力, HIVE 性能调优和业务的理解能力。
亲爱的朋友们:
别泄气,部分公司要招聘人,甚至都自己的平台都没有搭建好;
部分公司要招聘人,甚至都不知道你的特点是什么,能不能解决公司需求,也许只是觉得你可以来我们公司,好好培养培养。
所以,别轻易的泄气,觉得自己不行,做自己认为对的事情,然后继续努力,即使没有谁来告诉你未来的方向,你就要学会去总结和学习,才能活出真实的自己。
当然,要正确的意识到自己的不足,然后去弥补,别抱怨这个社会,因为抱怨没用。
That`s all !!!